Welcome to arbbt, Your OCD Time Tracker
February 09, 2021 Stardate: 74575.1 Tagged as: Arbtt Python
- arbtt
- The Automatic Rule-Based Time Tracker
I’m applying for a graduate program and in the meantime, while my application is being considered, I’ve started building out my LaTeX thesis template and workflow. I know it’s premature but I haven’t played with LaTeX since writing my Master’s Thesis nearly 15 years ago and wanted to reacquaint myself. After a couple of days, I was thinking to myself, “man, after the end of this I’m going to have a bunch of hours racked up.” So that thought experiment led me to look at time tracking software.
The one I thought was the “best” was arbtt, automated, rule-based time tracker.
Installation
Installation was very easy.
sudo apt update
sudo apt-get install arbttTell Ubuntu to start the daemon automatically on system start
cp /usr/share/doc/arbtt/examples/arbtt-capture.desktop ~/.config/autostart/Go ahead and manually start the daemon
(arbtt-capture &)And create your categorize.cfg file
~/.arbtt/categorize.cfgThat’s it
Categorization
This is where the magic is. arbtt tracks X properties like window title, class, and running programs, and you write rules to classify those strings. You can get as detailed as you want. For example, you can say “If Firefox is the active window (i.e. mouse or keyboard is working within it) and the title of the tab contains the word Twitter, than label all that accumulated time as Web_Twitter”. Something like that. Then you can apply regular expressions and complicated logic to figure out exactly what you want.
For a start, here are my “rules” in the categorization.cfg file.
-- A rule that probably everybody wants. Being inactive for over a minute
-- causes this sample to be ignored by default.
$idle > 60 ==> tag inactive,
-- Simple rule that just tags the current program
--tag Program:$current.program,
--tag Title:$current.title,
-- PYTHON
current window $program == ["Spyder"] ==> tag python,
-- THESIS
( current window $program == "evince" &&
current window $title =~ /dissertation/ ) ==> tag thesis,
current window $program == ["code"] ==> tag thesis,
( current window $program =~ /install4j/ ||
current window $title =~ /yEd/ ) ==> tag thesis,
-- WEB BROWSER
current window $title =~ [/LinkedIn/, /Twitter/] ==> tag Web:socialmedia,
current window $program == "Navigator" &&
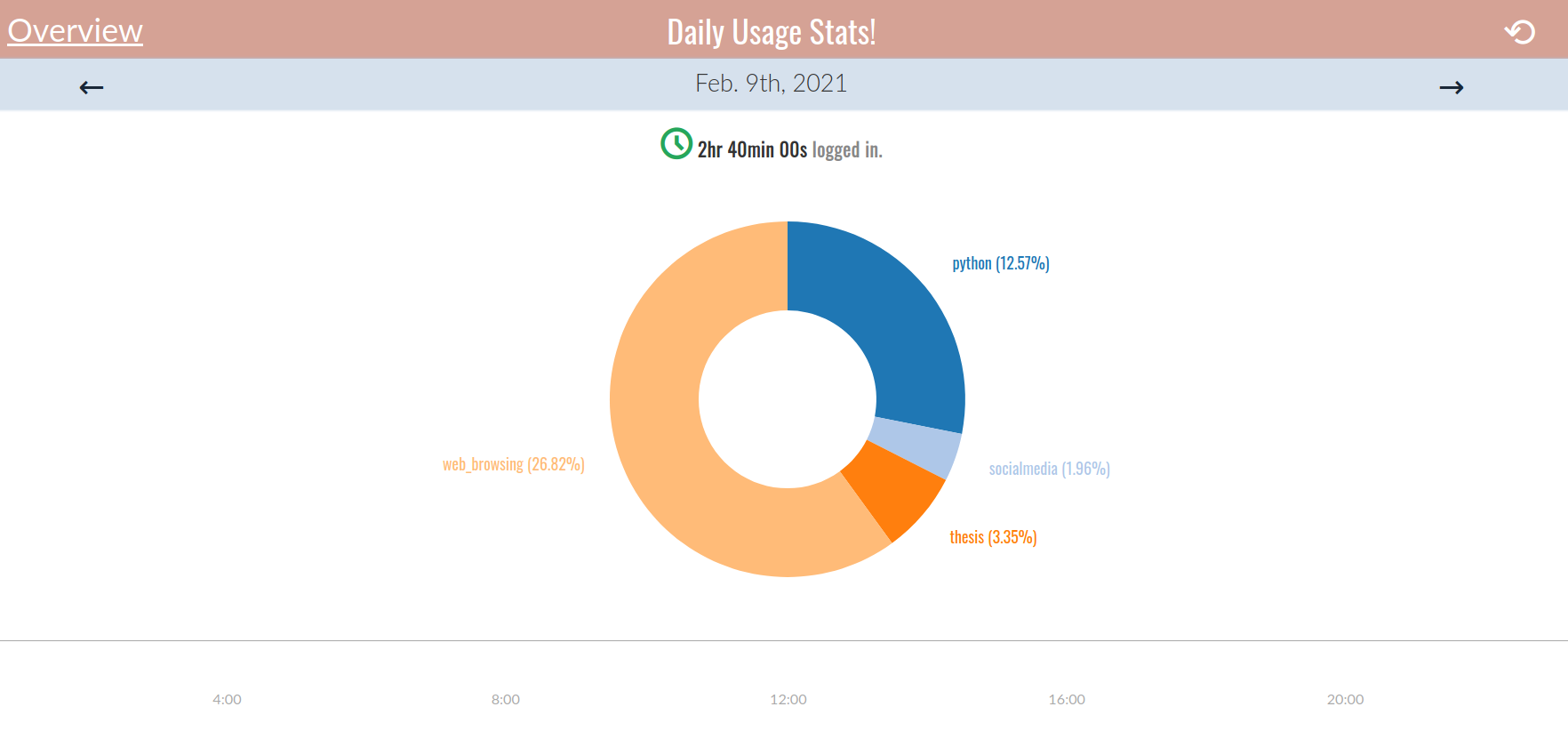
!(current window $title =~ [/LinkedIn/, /Twitter/]) ==> tag Web:web_browsing,I’m basically tracking three things; how much time I’m coding Python, working on my thesis, and wasting on social media. I was able to do this by just looking at the example file and trial-and-error. Then I can view the results:
joe@Praimfaya:~$ arbtt-stats
Processing data [================================================================================] 100%
Total time per tag
==================
_____________Tag_|______Time_|_Percentage_
Web:web_browsing | 1h33m00s | 27.43
python | 45m00s | 13.27
thesis | 12m00s | 3.54
Web:socialmedia | 7m00s | 2.06Cool!
Taking it too far = arbtt-graph
Of course, I will take it too far. There is an add-on names arbtt-graph that will take the data collected and serve a webpage with it all graphed out. Installation consisted of cloning the github repo and configuring the scripts. The workflow is to run the update bash script which dumps the arbtt-stats data into .csv files and then runs a python script to process the data and manipulate it into a json file. Then you run a python script that simply initiates a web server to display the html files from the “render” folder.
I ran into two problems that needed to be fixed.
- I don’t know if I had set it up wrong, but it didn’t like it when I had tags without categories. Meaning you can have tags like Web:general and Web:socialmedia, where “Web” was the category and “general” was the sub-tag. The python script assumed I would always have a category and barfed when I didn’t. I fixed this with try/catch blocks.
- I was greedy a combined the update and serving steps into a single bash file in path, so I could just call
timestats.shand update would get ran, a server is started on localhost, and a firefox tab is opened to the right page. The problem was all the files in arbtt-graph used relative paths so if I called from a random terminal directory it would barf again. I fixed by going into both python and bash scripts and changing to a absolute paths. This needs to be cleaned up and changed to directory variables because any change to the location and everything is screwed up again. But I was glad everything (arbtt-stats and -graph) was working so I left it alone.
Here’s what it looks like with my nominal setup.